One thing I do multiple times a day is browsing my company's GitHub organization repositories.
My process for opening these repositories in the browser is:
- Open Chrome
- Press Command + L to focus the address bar
- Start typing the GitHub repository name
- Look for the page suggestion and click on it
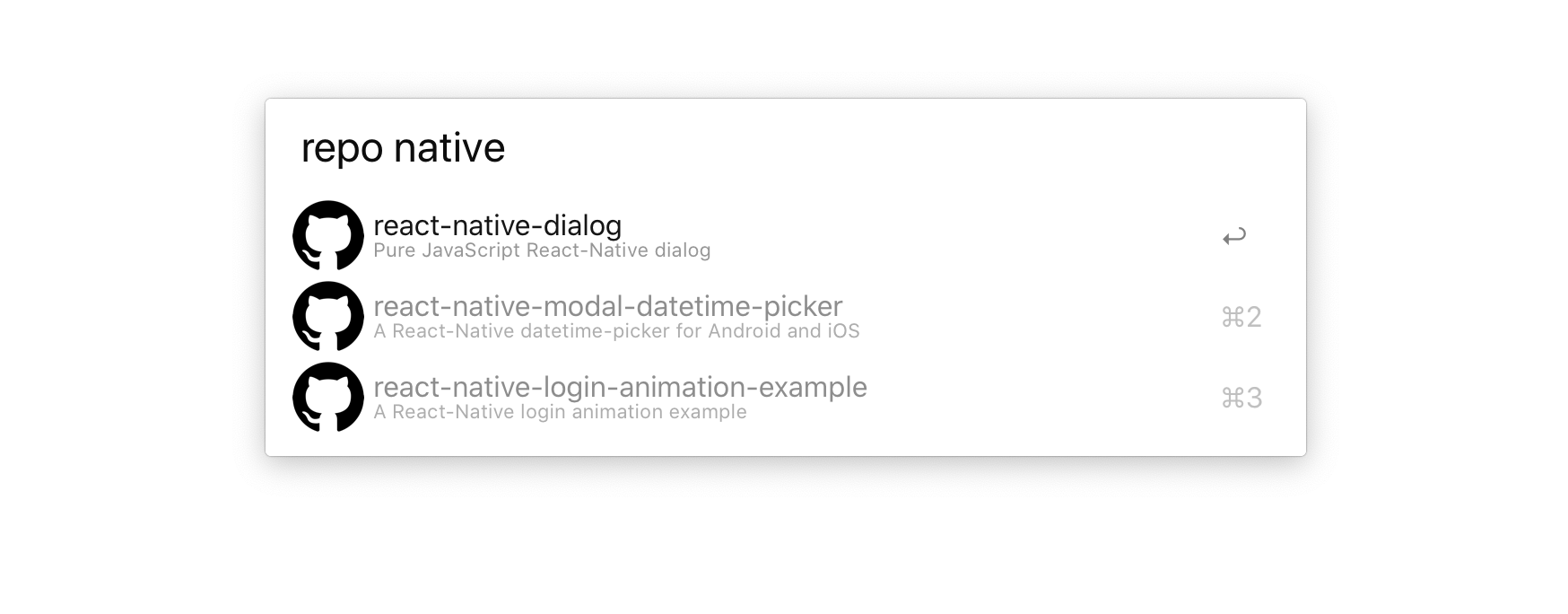
This flow works well for repositories that I have starred as bookmarks or that I browsed recently...
...But because I'm a total sucker for Alfred, today I wasted almost an hour moving this process into an Alfred workflow.
The Action Plan
Knowing that:
- The entire repository list is huge and doesn't change often
- I wanted the Alfred repository search result to be instant
Making an API request to filter the repositories each time I invoke the Alfred workflow wasn't an option.
So I decided to 1) download the entire repository list into a JSON file, 2) transform it into an Alred-compatible format, and 3) use the Alfred's fuzzy search helper to filter the results.
Creating the GitHub repository list
First of all, I created a GitHub API token with a scope to access the repositories list.

TIL: Selecting all the "repo" sub-scopes is not the same as selecting the entire scope -- which is needed to use the API token to get the list of all the private repositories.
The GitHub API pagination has a limit of 200 items per page. I needed to fetch way more than 200 repositories, so I modified this cool (but outdated) bash script to fetch all of them in a single command and print them out to the console:
#!/bin/bash
if [ ${#@} -lt 2 ]; then
echo "usage: $0 [your github credentials as 'user:token'] [REST expression]"
exit 1;
fi
GITHUB_CREDENTIALS=$1
GITHUB_API_REST=$2
GITHUB_API_HEADER_ACCEPT="Accept: application/vnd.github.v3+json"
temp=`basename $0`
TMPFILE=`mktemp /tmp/${temp}.XXXXXX` || exit 1
function rest_call {
curl -s -u $GITHUB_CREDENTIALS $1 -H "${GITHUB_API_HEADER_ACCEPT}" >> $TMPFILE
}
# single page result-s (no pagination), have no Link: section, the grep result is empty
last_page=`curl -s -I -u $GITHUB_CREDENTIALS "https://api.github.com${GITHUB_API_REST}?per_page=200" -H "${GITHUB_API_HEADER_ACCEPT}" | grep '^Link:' | sed -e 's/^Link:.*page=//g' -e 's/>.*$//g'`
# does this result use pagination?
if [ -z "$last_page" ]; then
# no - this result has only one page
rest_call "https://api.github.com${GITHUB_API_REST}?per_page=200"
else
# yes - this result is on multiple pages
for p in `seq 1 $last_page`; do
rest_call "https://api.github.com${GITHUB_API_REST}?per_page=200&page=$p"
done
fi
cat $TMPFILE#!/bin/bash
if [ ${#@} -lt 2 ]; then
echo "usage: $0 [your github credentials as 'user:token'] [REST expression]"
exit 1;
fi
GITHUB_CREDENTIALS=$1
GITHUB_API_REST=$2
GITHUB_API_HEADER_ACCEPT="Accept: application/vnd.github.v3+json"
temp=`basename $0`
TMPFILE=`mktemp /tmp/${temp}.XXXXXX` || exit 1
function rest_call {
curl -s -u $GITHUB_CREDENTIALS $1 -H "${GITHUB_API_HEADER_ACCEPT}" >> $TMPFILE
}
# single page result-s (no pagination), have no Link: section, the grep result is empty
last_page=`curl -s -I -u $GITHUB_CREDENTIALS "https://api.github.com${GITHUB_API_REST}?per_page=200" -H "${GITHUB_API_HEADER_ACCEPT}" | grep '^Link:' | sed -e 's/^Link:.*page=//g' -e 's/>.*$//g'`
# does this result use pagination?
if [ -z "$last_page" ]; then
# no - this result has only one page
rest_call "https://api.github.com${GITHUB_API_REST}?per_page=200"
else
# yes - this result is on multiple pages
for p in `seq 1 $last_page`; do
rest_call "https://api.github.com${GITHUB_API_REST}?per_page=200&page=$p"
done
fi
cat $TMPFILEI named the script githubapi-get.sh and used it this way:
# Get all the organization repositories:
githubapi-get.sh "{USERNAME}:{TOKEN}" "/orgs/{ORGANIZATION}/repos" > ~/my-company-repos.txt# Get all the organization repositories:
githubapi-get.sh "{USERNAME}:{TOKEN}" "/orgs/{ORGANIZATION}/repos" > ~/my-company-repos.txtFYI, you can also run it this way to get all the repositories you have access to (both on your personal account and on other organization accounts):
# Get all the repositories the user has access to:
githubapi-get.sh "{USERNAME}:{TOKEN}" "/user/repos" > ~/my-github-repos.txt# Get all the repositories the user has access to:
githubapi-get.sh "{USERNAME}:{TOKEN}" "/user/repos" > ~/my-github-repos.txtMaking the repository list compatible with Alfred
To populate the Alfred list filter, for each repo I extracted the following information:
uid: Unique identifier for the item which allows Alfred to learn about this item for subsequent sorting and ordering of the user's actioned results. I used the repository ID (id).arg: The argument which is passed through the workflow to open it in the browser. I used the repository URL (html_url).title: The title displayed in the result row. I used the repository name (name).subtitle: The subtitle displayed in the result row. I used the repository description (description).
Using the following jq script:
cat ~/my-company-repos.txt | jq -s '.[] | map({ arg: .html_url, uid: .id, title: .name, subtitle: .description }) | { items: . }' > ~/my-company-repos.jsoncat ~/my-company-repos.txt | jq -s '.[] | map({ arg: .html_url, uid: .id, title: .name, subtitle: .description }) | { items: . }' > ~/my-company-repos.jsonThe jq script generates a ~/my-company-repos.json file compatible with the Alfred Script Filter JSON format.
Creating the Alfred workflow
The Alfred standard script filtering doesn't have a good fuzzy search option -- which I really wanted given the huge amount of repositories.
As a workaround, I used alfred-fuzzy, a Python helper script for Alfred that replaces the "Alfred filters results" option with fuzzy search.
Here's what I did, step by step:
-
Create a new empty Alfred workflow
-
Right-click on the created workflow ⭢ "Open in Finder"
-
In the workflow directory, copy and paste both fuzzy.py and
my-company-repos.json. -
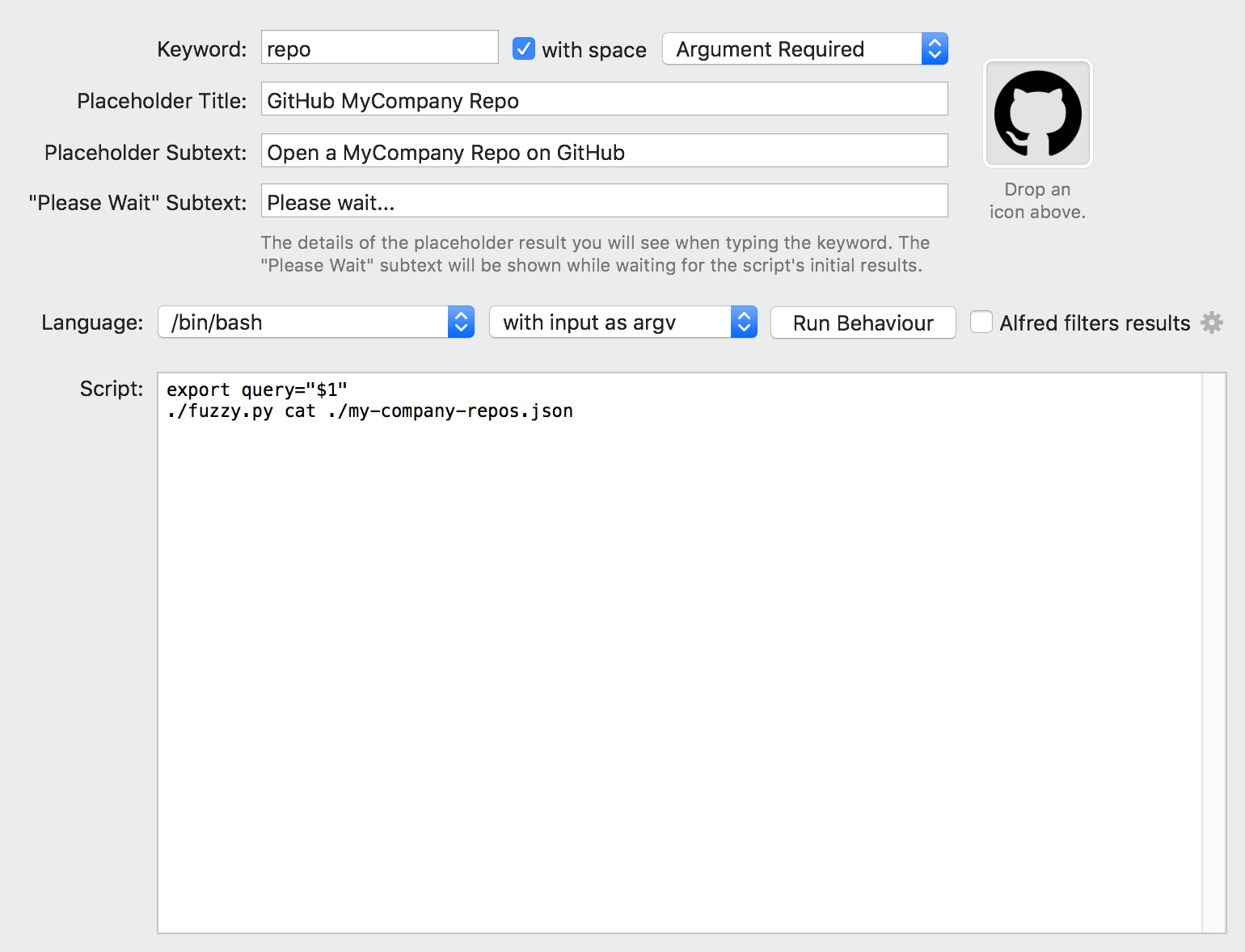
In the workflow, create the following "Script Filter":
-
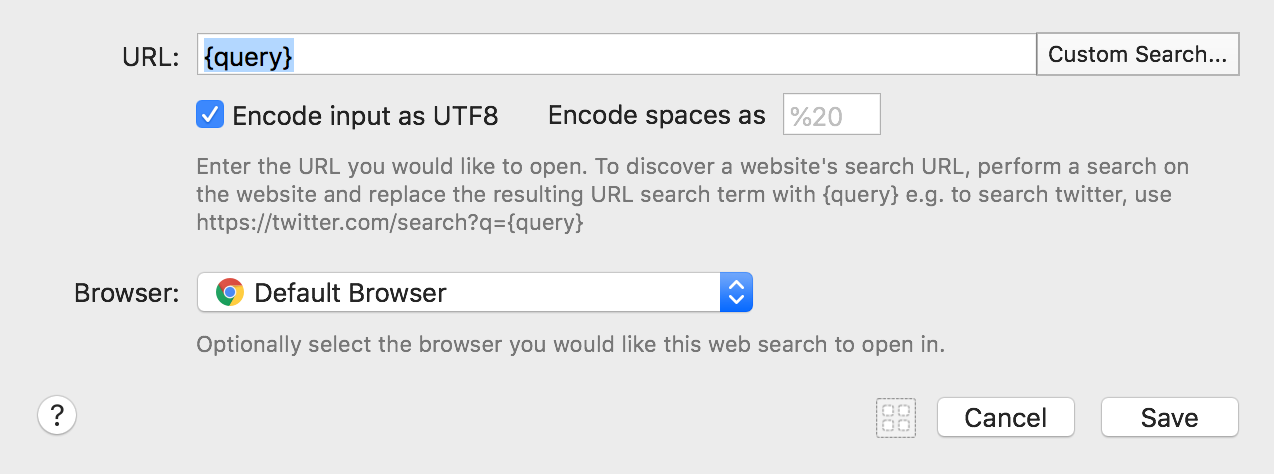
In the workflow, create the following "Open URL" action:
-
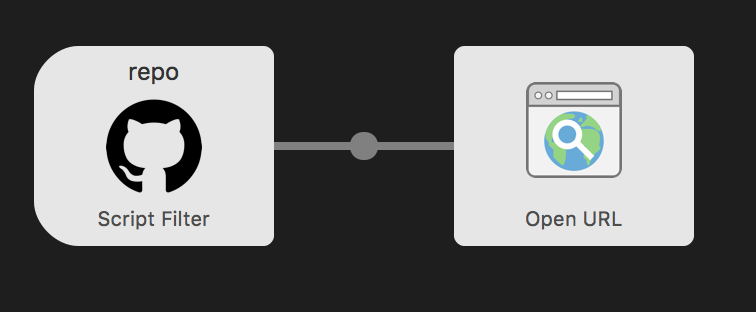
In the workflow, connect the "Script Filter" to the "Open URL" action:
That's it. I can now invoke the workflow using the keyword set in the "Script Filter" action and fuzzy search the repo I'm interested in.
Alfred is also smart enough to keep track of my workflow usage, surfacing the most clicked results to the top of the list 💥
Yes, the workflow can be improved in several ways (e.g.: auto-update the repository list after n days)... but I'm happy enough with the current result for now.