I'm open-sourcing Remotebear, a jobs aggregator that collects the latest remote opportunities from the best full-remote and remote-friendly tech companies.
You can find its source code on GitHub.
Some context
I started working on Remotebear (with Alex) a few months ago with the goal of creating a real "product" from the ground up — mostly for fun.
Building this kind of websites can be simple, but you can also spend a ton of time obsessing over details almost no user will ever care about... like:
- deciding where to store your content
- trying multiple normalization strategies for different job boards
- making the website work with JavaScript disabled
- spending time on designing the "branding", coming up with a catchy name and a logo
- dealing with custom caching logic, CSP, etc...
Which, of course, is where I spent most of my development time 🙄
Open-sourcing Remotebear
I "published" Remotebear around a month ago, but I haven't promoted it much besides sharing it on Hacker News and Indie Hackers.
Given that:
- Remotebear has never been more than a side-project
- (as of today) I'm not planning to monetize it in any way
- a few people asked "how" it works under-the-hood
...I think it kinda makes sense to just open-source it.
You can find Remotebear's source code on GitHub.
Technology & Architecture
Remotebear is a NextJS web application that gathers job offers from public APIs and by scraping public websites using a Node script. The entire codebase and "database" are contained in the remotebear-io/remotebear repo and is organized using Yarn Workspaces.
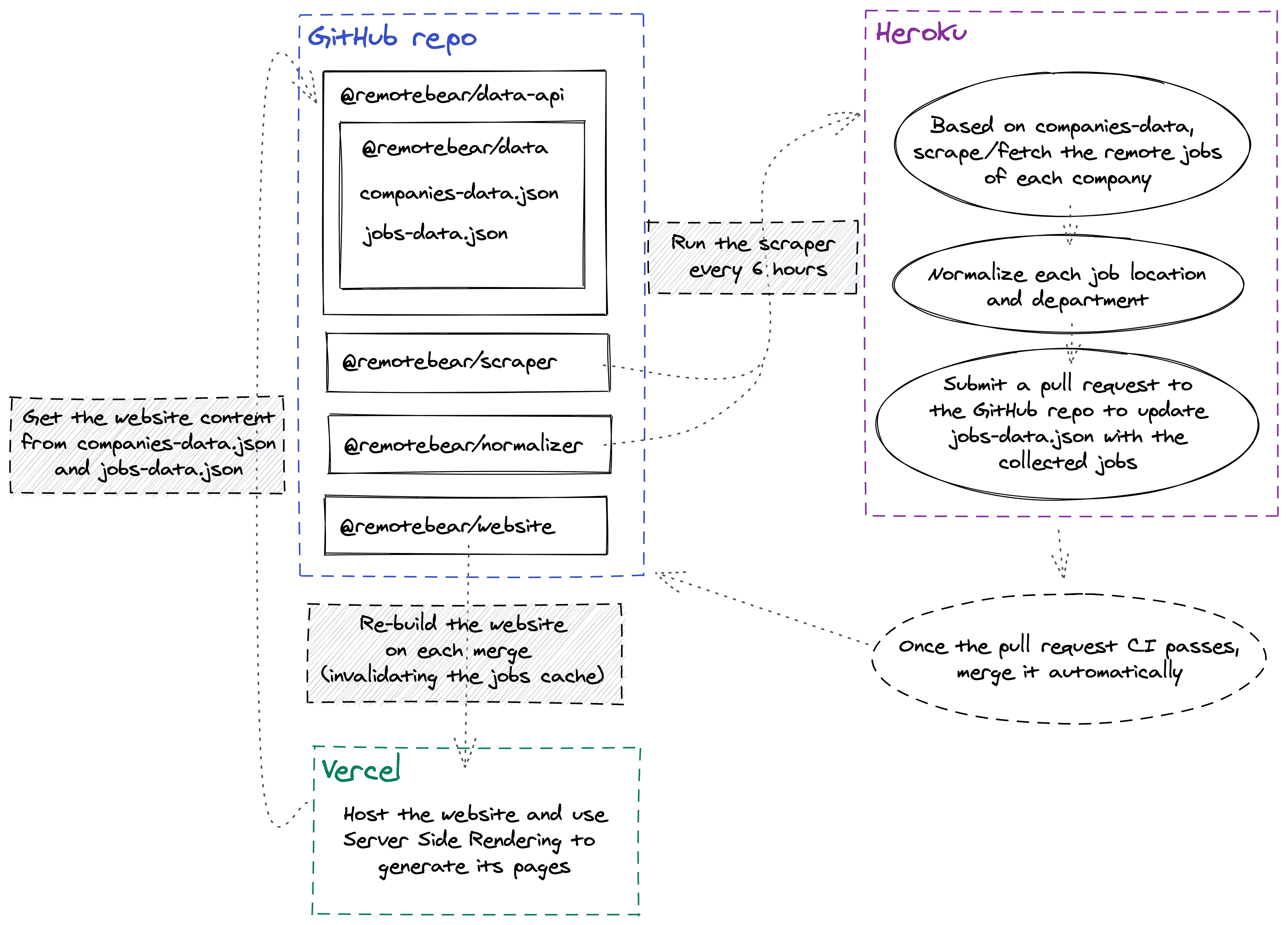
The way Remotebear collects remote jobs is the following:
- In the repo I'm storing a
companies-data.jsonfile, which keeps track of what companies we're interested in. It holds information about the company name, URL, description, and about how their remote positions should be collected (AKA from which job board, like Greenhouse, Lever, etc...). - Every
nhours, I run a Node script on Heroku that, givencompanies-data.json, collects each company remote job, normalizes it (e.g.: normalize locations like "Remote - New York only" into more scoped "us", "eu", "global" buckets), and submits a pull request to the repo with the goal of saving the collected remote jobs in a JSON file calledjobs-data.json. - If the pull request tests pass, Bulldozer automatically merges it.
Here's how a pull request looks like:
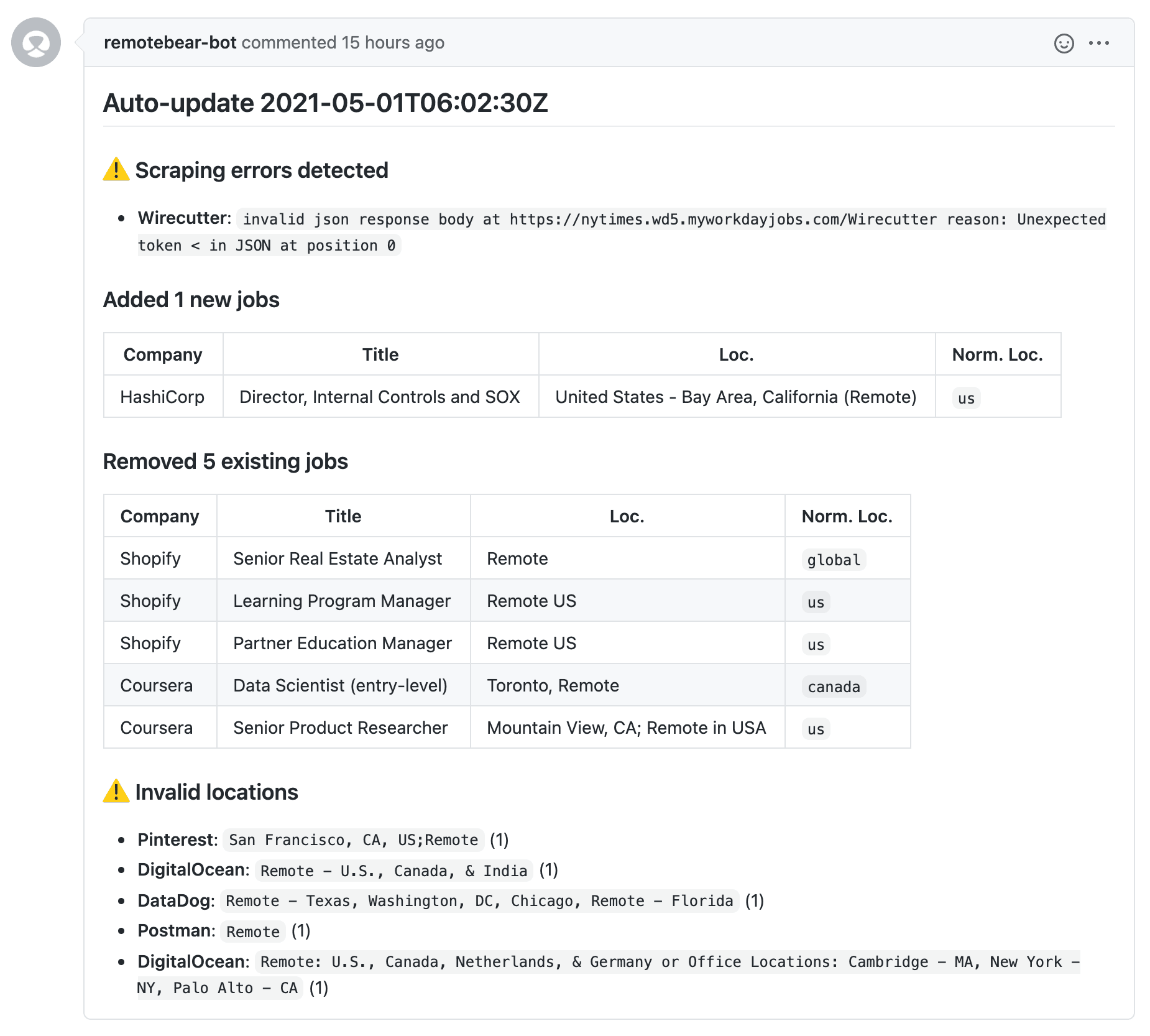
All the static data that populates Remotebear lives in the repo as huge JSON objects.
Why? Because this pattern is working well enough for our current use case.
Does it scale well? No.
Are we planning to scale? Who knows.
Remotebear's website is built with NextJS, is hosted on Vercel, and uses Server Side Rendering for the pages generation. It grabs the jobs/companies data from NextJS serverless functions that expose jobs-data.json and company-data.json (they just read them once loaded and keep them in memory).
For jobs and companies data, we set a long caching window at the edge. We never show stale data because every time a pull request is merged, Vercel starts a new build, invalidating the entire jobs/companies cache.
Immutable assets (e.g.: fonts, images, etc...) are also cached on the browser.
Basically, the way we store and use data on the front-end is a mixture between Static Site Generation and Server Side Rendering; we're not going all-in with a Static Site Generation approach because pagination, search, and filtering, would still require some kind of Server Side Rendering to generate the pages on-demand.